深層学習っぽい用語のメモ 〜 Auxiliary loss、Transformer-XL、axial-attention〜
AlphaFold2はディープラーニングの専門家の視点でみても面白いそうですが、ど素人にはさっぱりです。 というわけで、前回の「Self distillation」に引き続き、深層学習っぽい用語を調べています。
今回取り上げる用語はAuxiliary loss、Transformer-XL、axial-attentionです。
概要
むりやり1枚にまとめるとこんな感じの話です。

初めに青枠の①auxiliary lossをみます。損失計算における工夫で、勾配消失といった課題と関わりそうです。
次に緑枠、Transformerの固定長という制限を取り除こうとする取り組みをみます。auxiliary lossを応用した②vanilla modelや、その改良版③Transformer-XLです。
最後に赤枠、画像認識へのSelf-attentionの応用(④)をみます。改良版として、2Dデータの処理を軸方向の1Dの組み合わせに落とし込んだ⑤axial-attentionがでてきます。Transformer-XLで出てくる相対的位置符号化の考え方はこっちにも顔を出します。*1
では順番に見ていきましょう!
1. Auxiliary loss
1-1. こまめな中間報告が成功の鍵? ~補助損失~
「Auxiliary loss(補助損失)」は2014年の画像認識のコンペティション ILSVRC(ImageNet Large-Scale Visual Recognition Competition)で優勝したモデル GoogLeNet で利用され、有名となった手法のようです。
- 文献①: C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich.
Going deeper with convolutions. In Proc. of CVPR, 2015. arXiv.:1409.4842v1
GoogLeNetは下図のようなアーキテクチャーのネットワークです。めちゃくちゃディープで複雑なので途中で分割してます。
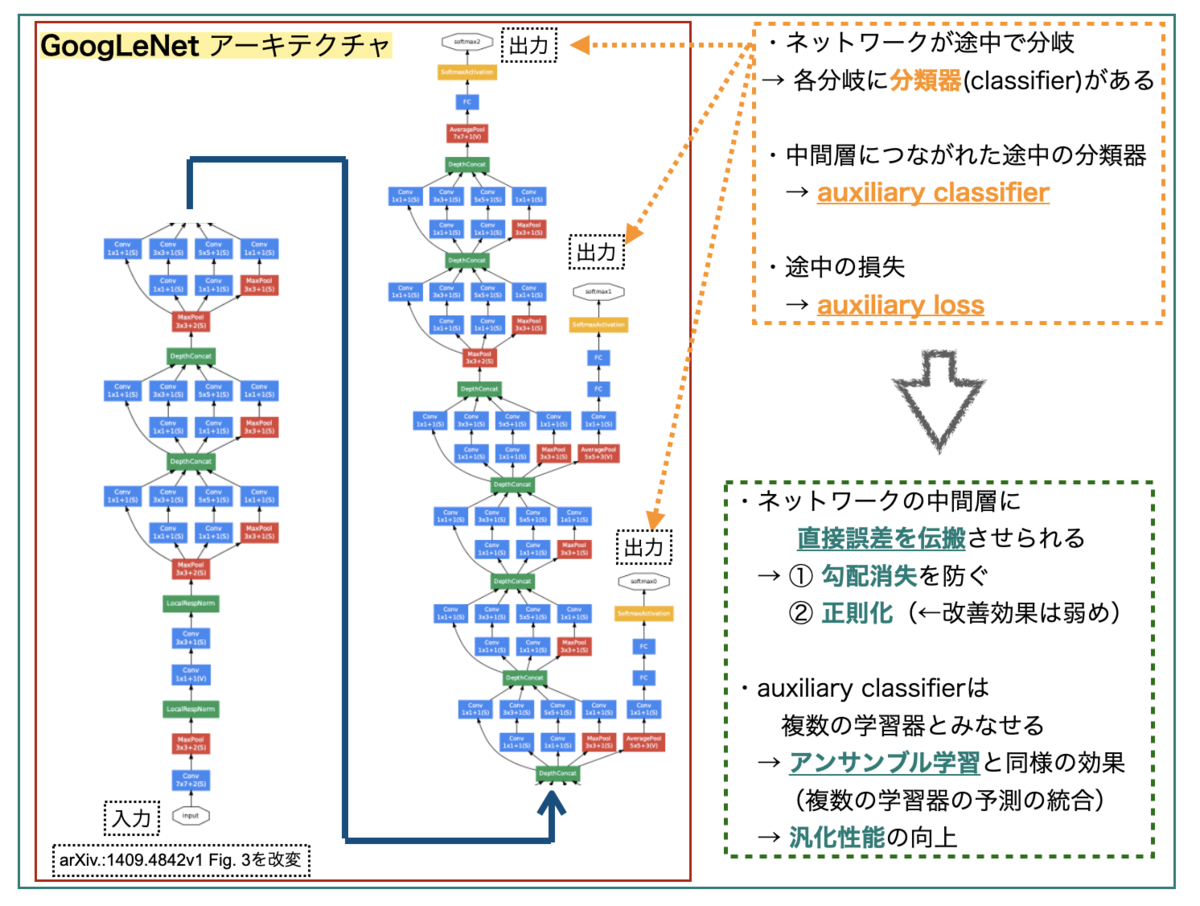
GoogLeNetの特徴の一つは、ネットワークが途中で分岐してサブネットワークを構成していることです。*2ネットワークの最後だけでなく、各サブネットワークにもそれぞれクラス分類器(classifier)があり、auxiliary classifierと呼ばれています。 これらから求められる損失がauxiliary lossとなります。
巨大なネットワークでは「全ての層に勾配を効率的に伝搬するのが難しい」という課題があります。GoogLeNetでは、中間層にauxiliary classifierが繋がっていることで、中間層に直接誤差を伝搬することができ、① 勾配消失を防ぐ、② 正則化を実現できる*3、といった利点があるそうです。*4
また、複数のクラス分類器があるので、アンサンブル学習(複数の学習器の予測結果を統合)と同様の効果が得られ、汎化性能を高めることが期待できるそうです。*5
巨大なモデルの途中途中で、評価とフィードバックをうけるとうまくいく、って感じでしょうか?深層学習でもこまめな進捗の報連相、大事なんですねー。
1-2. AlphaFoldででてくるAuxiliary loss
AlphaFold2では学習に使う損失関数として、タンパク質立体構造予測のための特別な「FAPE (Frame Aligned Point Error)」というオリジナルな損失を作成しています。 さらに学習では、FAPEに加えて多数の「補助的な(Auxiliary)損失」を合わせて使っています。

上図のL_auxはStructure Moduleで計算されるauxiliary lossです。Structure Moduleは8層(8 blocks)の積み重ねとなっています。 各層ごとに、その時点での中間的な3次元構造について損失を計算し、最後にすべての層での損失の平均を取ってL_auxとしています。
L_auxはFAPE損失とねじれ角損失(torsion angle loss)を足し合わせたものです。この中間的な損失では計算負荷を減らすため、 FAPEは主鎖Cαのみ、側鎖に関する損失はねじれ角のみにする、という工夫が行われているようです。
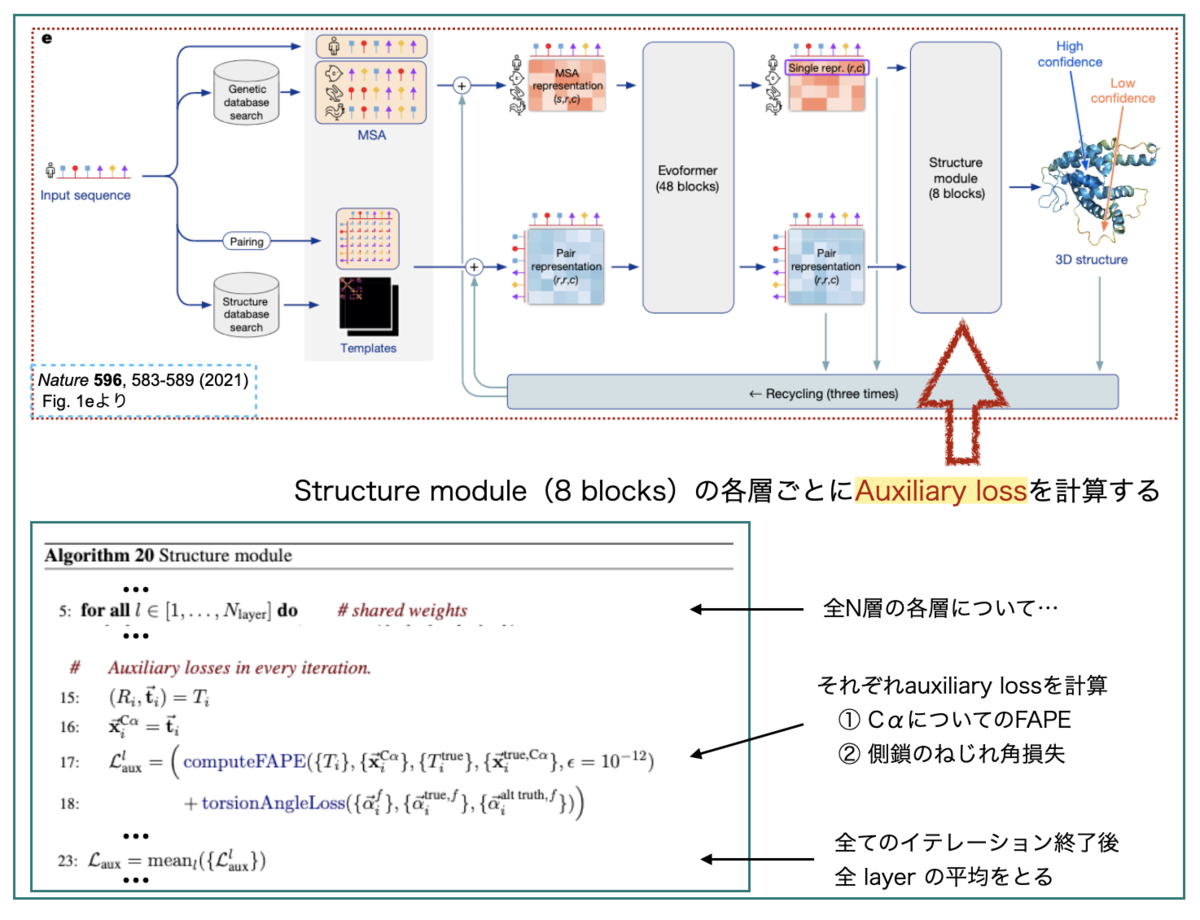
GoogLeNetの時と同様に、途中結果の損失評価を挟むことで、巨大なモデル全体の学習を成り立たせたり、汎化性能を高めたりできてる、ということでしょうか??
1-3. Auxiliary lossの効果はあったの? ~ablation study~
Auxiliary lossでやりたいこととAlphaFold2での使われ方はだいたい分かりましたが、実際のところどれくらい効果があったのでしょうか?
AlphaFold2の文献では評価実験も報告されています。「複雑な構成要素の一部を取り除いた手法」を「オリジナルの手法」と比較する評価実験を ablation study というそうです。*6
本文 Fig. 4a(下図)に結果、Supplementary Information 1.13に詳細な説明が載っています。

異なるベースラインのシード3つで実験した平均で比較しているので、各要素それぞれ3本ずつ結果があるようです。
「No auxiliary distogram head」や「No auxiliary maked MSA head」がauxiliary lossに関連する項目となりそうでしょうか? 概してベースライン(縦線)より小さくなっているので、「元々のモデルでは精度に貢献していた」ということになりそうです。
Supplementary Informationのコメントを引用しておきます。
Finally, careful handling of the structure and intermediate losses (using both end-to-end structure gradients and providing intermediate loss gradients in recycling) is important to achieving full accuracy. This is likely due to pushing the network towards having a concrete representation of the structure as appears to be present in the trajectories of intermediate structure predictions.
(Supplementary Information p51 強調は追加)
良かった良かった(?)
2. Transformer-XL
次の用語はTransformer-XLです。XLはextra longの意です。
- 文献②:Z. Dai, Z. Yang, Y. Yang, J. Carbonell, Q. Le, and R. Salakhutdinov.
Transformer-XL: Attentive language models beyond a fixed-length context. arXiv:1901.02860v3
AlphaFold2はTransformerをベースにしたモデルですが、Trasformerには「固定長しか扱えない」という制限があるそうです。これをうまく克服したのがTransformer-XLで「セグメントレベルの再起」と「相対位置符号化」がポイントだそうです。 *7
Transformer-XLの論文の中身を見る前に、論文中で比較されている以前のモデルを見ておきましょう。
2-1. Transformer x Auxiliary lossで文字レベル言語モデルの高性能化
- 文献③:R. Al-Rfou, D. Choe, N. Constant, M. Guo, and L. Jones.
Character-level language modeling with deeper self-attention.arXiv:1808.04444v2
文献③は、LSTMやRNNが高性能を発揮していた「Character-Level Language Modeling」でも、Transformerを使うことでより高い性能が出せることを示した文献です。
Character-Level Language Modelingは、「単語(word)レベル」ではなく「文字(character)レベル」の言語モデルのことで、ここで扱われているのは「入力の文字列から次の文字を予測」するタスクです。*8
文献③ではディープ(64層)なTransformerモデルを使っていますが、成功の鍵として「中間層および配列の中間位置にauxiliary lossを加えたこと」を上げています。これにより「収束のスピード」を上げることができ、より深いネットワークの学習ができたそうです。
モデルの構造をステップ・バイ・ステップでみるとこんな感じです。中間位置、中間層、複数ターゲットの予測とタスクを増やして、それぞれで補助損失(auxiliary loss)を計算するという構造になっています。

また、「文字の位置情報の取り扱い(Positional embedings)」も工夫しています。
深いモデルでは、入力の段階にだけ位置情報を付け加えても、層間の伝搬中に情報が失われる可能性があります。そこで、各transformer層に入る前の入力配列に、層毎に学習する「位置の埋め込み(positional embedding)」を加えています。
以上のようなモデルにより高い精度を発揮することができたとのことです。Auxiliary lossがここでも活躍していますね。
くどい感じに図を引用しましたが、この図の見方がわかるとTransformer-XLの図が少し分かりやすくなります。
2-2. Transformer-XLと可変長文字列の取扱い
Transformer-XLの利点は「可変長を扱える」ことで、ポイントは「① セグメントレベルの再起」と「② 相対的位置符号化」とのことでした。順番にみていきます。
2-2-1. セグメントレベルの再起(Segment-level Recurrence)
まず①について、比較対象として「(再起のない)セグメント化モデル」があげられています。これが先の文献③です。
可変長を扱うには、「どうやって長文を固定長の表現に符号化(encode)するか?」が課題となります。単純に「制限のないTransformerを用意して全文を投げ込む」のでは膨大な計算リソース必要で現実的ではありません。
文献③のアイデアは「コーパス全体を、扱いやすいサイズの短いセグメントに分割し、各セグメント内部でだけ訓練を行う」というものです(文献②ではvanilla modelと呼んでいます)。このモデルでは、セグメント間での情報のやりとりはありません。
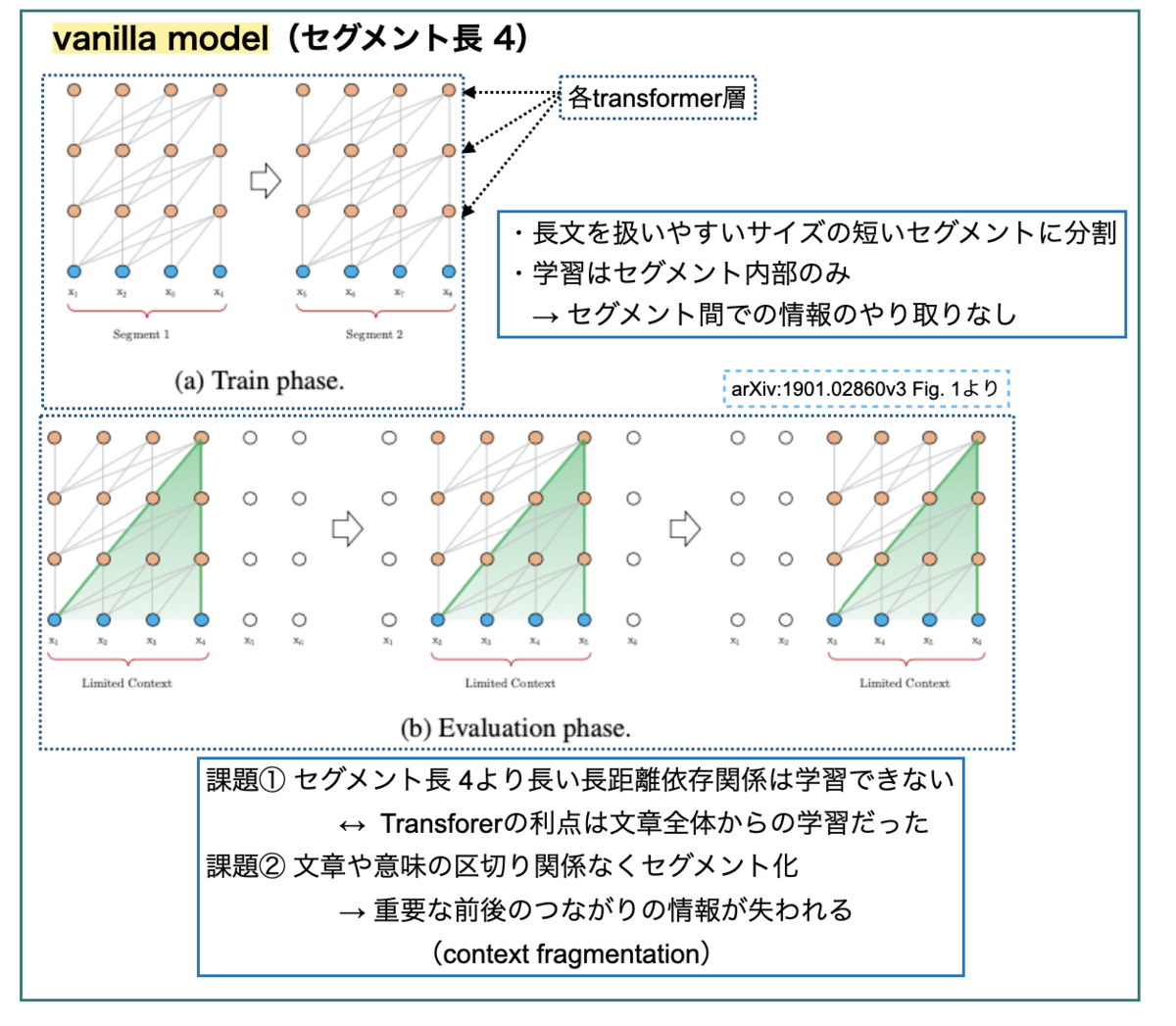
vanilla modelの限界として2点指摘されています。
- 決まった長さ以上の長距離依存関係が学習できない(上限がセグメントの長さ)
- 文章や意味の区切りを考慮せずにセグメントに切り分けることで重要な情報が失われる(context fragmentation)
以上の課題を解決するため、Transformer-XLは「再起メカニズム(recurrence mechanism)」を導入しています。文献② Fig.2 を見るとイメージしやすいです。

前のセグメントの「隠れ状態配列(hidden state sequence) 」を計算し、固定化・キャッシュ化します(Fixed(No Grad))。これを次の新しいセグメントを処理する際に「拡張文脈(extended context)」として再利用します。
このように「セグメントレベルで再起処理」を行うことで、セグメント境界を超えた情報の伝達が可能になり、長距離依存関係の学習ができたり、context fragmentationが解消できる、ということのようです。
2-2-2. 相対的位置符号化(Relative Positional Encoding)
文献②(vanilla model)で位置情報の取扱いについてふれましたが、Transformer-XLでは「隠れ状態」を再利用するようにしたことで新たな問題が生じました。
標準的なTransformerでは、位置情報は「絶対的(absolute)な位置」として表せば十分で、これはセグメント内部でしか情報をやりとりしない vanilla modelでも一緒です。
一方、セグメント間のやり取りのあるTransformer-XLで「セグメント内の絶対的位置」([0, 1, 2, 3])を使ってしまうと、「隠れ状態(前のセグメント)の内部における位置」との区別ができなくなってしまいます([0, 1, 2, 3, 0, 1, 2, 3])。
そこで「隠れ状態の「相対的(relative)な位置情報」だけをエンコードするようにしよう!」というのが「相対的位置符号化」です。
TransformerのAttention操作について考えると、計算するだけならqueryとkeyの「それぞれのベクトル内部での絶対的位置(i、j)」がわからなくても、「相対的な距離(i-j)の情報」さえあれば十分計算できるよね、ってことみたいです。
なお、相対距離がわかっていれば、後から再起的に絶対的な位置情報を取得することができるそうなので安心(?)ですね。
「Relative positional encodingを実際にどのように行うか?」は文献③中、また以下の記事で丁寧に解説してくださっています。*9
2-3. AlphaFold2と相対的位置符号化
AlphaFold2でTransformer-XLが引用されている箇所は「Supplementary Information 1.5 Input embeddings」です。
ペア表現(pair representation)について、鎖(chain)における残基の位置の情報をネットワークに与える際に「相対的な位置の特徴(relative positional features)」をエンコードしています。
具体的には、Algorithm 4のように、最大値 32で区切ってone-hotベクトル表現としています。相対的距離(差)で表すやり方がTransformer-XLに類似しているとのようです。

「実験的には、相対的なエンコードにより、学習に使った配列よりも長い配列に対しても質を落とさずにネットワークを評価することができる」とのことですが、このあたりTransformer-XLのEvaluation Phaseでセグメントを超えた情報伝達が行われている、という点と関連があるのでしょうか??
2-4. 相対的位置符号化とAlphaFold2の複合体予測
可変長を扱えるTransformer-XLについて、AlphaFold2では「相対的位置符号化」の技術が転用されているようでした。この技術について、AlphaFold2をGoogleColab上で使えるようにし、さらに機能の拡張をおこなったColabFold論文で面白い指摘がされていました。
- 文献④: M. Mirdita, S. Ovchinnikov and M. Steinegger
ColabFold - Making protein folding accessible to all bioRxiv 2021.08.15.456425
先に見た通り、AlphaFold2では「 |i-j|≧ 32でキャップした相対的位置符号化」を使っています。従って、32以上離れた残基のペアはどれでも、同じ相対的位置符号化がなされることになります。 つまりAlphaFold2は、2つのタンパク質間の残基のインデックスを32よりも大きく離せば、それぞれ別々のポリペプチド鎖として扱う、といことになります。
これを踏まえて、AlphaFold2でタンパク質-タンパク質複合体予測を行いたい場合には、「それぞれの鎖の間に32残基分より大きく間隔をあけてつないで入力すれば良い」らしく、ColabFoldにおける複合体予測機能の実装に利用しているそうです。
「なぜAlphaFold2で複合体予測がうまくいくのか?」という問いの答えにはなっていませんが、モデルの仕組みを利用して新しい機能の実装につなげているのは面白いですね。
3. axial-attention
最後に取り上げる用語はaxial-attention(もしくはcriss-cross atention)です。
元々は、「画像認識の分野Attentionを使いたい」というところから来ているようです*10。ざっくり「2次元データの各軸方向にattentionを使うぜ!」って感じみたいです。
AlphaFold2では、本文(ref. 53)とSupplementary Information(ref. 118)にそれぞれ関連する文献が引用されています。
- 文献⑤: H. Wang, Y. Zhu, B.Green, H. Adam, A. Yuille and L.-C. Chen
Axial-DeepLab: Stand-Alone Axial-Attention for Panoptic Segmentation arXiv:2003.07853v2 - 文献⑥: Z. Huang, X. Wang, Y. Wei, L. Huang, H. Shi, W. Liu and T. Huang
CCNet: Criss-Cross Attention for Semantic Segmentation arXiv:1811.11721v2
3-1. 画像認識へのAttentionの利用
以下の記事がとても分かりやすかったです。
単純に画像認識のConvolutionをSelf-Attentionに置き換えた初期の例として以下の文献があるそうです。
- 文献⑦: P. Ramachandran, N. Parmar, A. Vaswani, I. Bello, A. Levskaya and J. Shlens
Stand-Alone Self-Attention in Vision Models arXiv:1906.05909v1
畳み込みの空間領域に局所的なattention層を当てはめています。こういう感じ。

位置情報は、相対的距離(relative distance)を利用して取り込んでおり、relative attentionと呼んでいます。

Transformer-XLを見た後だとやりたいことが分かりやすいですね。
3-2. 軸毎に切ったattentionで画像の広範囲を取り込む ~axial-attention~
画像認識に対してAttentionを使う雰囲気は分かりましたが、先の例は局所的な領域(ex. 3x3)への適用でした。 元々のTransformerに「自然言語処理で文章全体からの情報を利用したい」というモチベーションがあったことを考えると、画像認識でも同様に「範囲をより広く全体に広げたい」という気持ちになりそうです。
これは画像認識のパノプティックセグメンテーションというタスクと関係してくるようです。*11

上のようなタスクを行うには、モデルが認識できる画像の範囲(受容野, receptive field)を広くとって、局所的ではなく大域的な空間関係を把握することが大事となってくるようです。
画像認識のAttentionでも範囲を広げたくなりましたが、2次元で領域を単純に広げるのは計算コストがかかりすぎて難しいそうです。そこで「2次元ではなく1次元で軸方向にattentionを使うことでこの問題を回避しよう」というのが文献⑤です。*12

上図のように、「高さ軸方向(hight-axis)」と「幅軸方向(width-axis)」の1D attentionを順次適用しています。これにより、2D attentionよりも計算効率を改善し、大域的な情報(広い受容野)を使用することができるようになった結果、パノプティックセグメンテーションのタスクで良い結果を示したそうです。
また、axial-attentionでは文献⑦よりも「相対的位置符号化(relative positional encoding)」を拡張していて、keyだけでなく、queryとvalueにもpositional biasを加えています。

以上がaxial-attentionの概要でした。
3-3. AlphaFold2でのaxial-attention
AlphaFold2でaxial-attentionが出てくるのは、EvoformerのMSA部分です(Supplementary Information 1.6 Evoformer blocks)。 入力の多重配列アラインメント(MSA)に対して、行・列それぞれについて「MSA row-wise gated self-attention」(SI 1.6.1)と「MSA column-wise gated self-attention」(SI 1.6.2)を利用しています。

また、Ablation Studyの一つ「No triangles, biasing, or gating (use axial attention)」(SI 1.13.1)では、row-wise MSA attentionのペアバイアス(pair bias)を「投影された相対的距離(relpos_ij)」と置き換えた後、すべてのattention操作からゲートを取り除いたモデルを作成しています。
このような修正を加えてシンプルにしたものは、文献⑥に出てくるような「標準的なaxial attention(あるいはcriss-cross attention)」とほぼ似たような構造となっているそうです。
4. まとめ
以上、今回は前回に引き続きAlphaFold2に出てくる深層学習っぽい用語、Auxiliary loss、Transformer-XL、axial-attentionについてでした。
色々なテクニックを取り入れられて作られているとは、方々で目にしていましたが、調べれば調べるほど色々なトピックがでてきてびっくりしています。「この単語1語の背景に先行研究がたくさんあったのか!」の連続です。
また、用語を検索したら日本語で解説してくださっている記事が出てきて、「インターネットの賢い人たち本当にありがとう」と感謝しきりでした。参考にさせていただいた記事は全て本文と脚注に記載したつもりですが抜けていたら教えていただけると嬉しいです。
深層学習の用語というわけではありませんが、「Ablation Study」がスタンダードな評価実験の方法、というのもつでいに分かって、AlphaFold2文献の中で意味のわかるFigureが少し増えました。Figureに書かれている効果の大きさがどれくらいなのかはピンときませんでしたが。。。
以上、今回も適当に切り貼りした記事になってしまいました。間違いがとても多そうなのでご指摘いただければ幸いです。ではでは。

*1:研究の時系列とは関係なく、今回の記事のお話の流れです。すみません
*2:他にもInceptionというモジュールを使っていることなど、魅力的な特徴はいっぱいあるそうですがここでは割愛します。
*4:参考: 内田 祐介 山下 隆義「物体認識のための畳み込みニューラルネットワークの研究動向」電子情報通信学会論文誌D Vol.J102-D No.3 pp.203-225
*5:ディープラーニングのE資格の例題としてでてきました。 参考: Qiita DNN_後編2 (確認テストの考察)
*6:参考:「研究における評価実験で重要な7つのこと」
*7:参考①:Google AI Blog 解説記事「Transformer-XL:Unleashing the Potential of Attention Models」
参考②:WebBigDataさんによる参考①記事の翻訳 「Transformer-XL:Attentionモデルの可能性を解き放つ」
参考③:楽しみながら理解する自然言語処理入門「Transformer-XLを理解する」
*8:文字を扱う「Character-Level Language Modeling」は以下の点で難しいそうです。
1. 単語の語彙を「1から」学習しないといけない
2. 自然言語のテキストは何百・何千ものステップを介した長距離依存を示す
3. 文字列は単語列よりも長くなるので計算のステップ数がかなり多くなる。
*9:私にはさっぱりわからなかったです。
*10:参考:Qiita「画像認識でもConvolutionの代わりにAttentionが使われ始めたので、論文まとめ」
*11:参考:SkillUp AI 深層学習を用いたセグメンテーションの紹介 セグメンテーションシリーズ①
参考文献:A, Kirillov, K.He, R. Girshick, C. Rother and P. Dollár Panoptic Segmentation arXiv:1801.00868ve
*12:参考①:Google AI Blog 解説記事「Axial-DeepLab: Long-Range Modeling in All Layers for Panoptic Segmentation」
参考②:WebBigDataさんによる参考①記事の翻訳 「Axial-DeepLab:パノプティックセグメンテーション用にattentionを改良(1/2)」
「Axial-DeepLab:パノプティックセグメンテーション用にattentionを改良(2/2)」