Self Distillationって何?AlphaFold2では何をしているの?
先日AlphaFold2についてのPodCastを聞きました。知らないことばかりで「あーなるほどそういう話だったのかー」と興味深かったです。専門の先生方の議論を拝聴できるのはすばらしいですね。
AlphaFold2はディープランニングの専門の方から見ても、面白い技術がたくさん使われているそうですが、ど素人にはそもそもどこが生物学で、どこが深層学習的な話なのかわからないです。
というわけで、今回は深層学習の用語らしい「Self distillation」について調べてみました。ついでにAlphaFold2での使用例もちょっと見たいと思います。
1. Self distillation
Slef distillationはネットワークの学習の際に用いられる工夫だそうです。
「①Konwledge distillation(知識蒸留)」という異なるモデル間での学習結果の移植を、自分自身(同じモデル間)で行ってパフォーマンスの向上を行ったのが「②Self distillation(自己蒸留)」です。
さらにSelf-Training(自己訓練)で、学習時にノイズを追加したら精度と頑健性が上がったというのが「③Noisy Student Training」というもののようです。
- 文献①: Hinton, G., Vinyals, O. & Dean Jeff. Distilling the Knowledge in a Neural Network (arxiv:1503.02531v1)
- 文献②: Zhang, L., Song, J., Gao, A., Chen, J., Bao, C. & Ma, K. Be your Own Teacher: Improve the Performance of Convolutional Networks via Self Distilation (arxiv:1905.08094v1)
- 文献③: Zie, Q., Luong, M.-T., Hovy, E. & Le, Q.V. Self-training with Noisy Student improves ImageNet classification (arxiv:1911.04252v4)
AlphaFold2では「SI:1.3 Self-distillation dataset」で文献③が引用されていますが、折角なので順番に見ていきます。
1-1. 知識蒸留はモデル圧縮の技術
知識蒸留はGeoffrey Hinton*1らにより提案されたモデル圧縮(Model compression)の手法です(文献①)*2。
ディープラーニングのネットワーク構造は精度を高めるために多層・複雑になっています。モデルが複雑になると特徴の学習がうまくいくようになりますが、学習したモデルを使って推論を行うコストも大きくなってしまいます。アプリやサービスで実際に運用(デプロイ)するには推論の速さや計算負荷も重要になるので、モデルの大きさがネックになります。
そこで、「別に学習の段階と推論の段階が同じモデルである必要ないよね!それぞれの段階に合わせたモデル使えばいいよね!」ってのがこの論文の主張です。Introductionでは「昆虫だってエネルギーを蓄える幼虫の段階と、移動して繁殖する成虫では全く体の構造が違うでしょ。機械学習だってトレーニングとデプロイで、それぞれの段階の目的に合わせた最適な構造にしようぜ!」っていってます。・・・たぶん。

具体的には「学習用の大きなモデル」と「推論用の小さなモデル」を用意します。予め大きなモデルで高い精度が出るように学習しておき、次に、小さなモデルを大きなモデルと同じ推論ができるように学習させます。前者を教師モデル(Teacher Model)、後者を生徒モデル(Student Model)と呼ぶことも多いようです。*3
小さなモデルであれば、性能が弱い端末上でも動かすことができるので、さまざまな現場で利用可能性が広がります(ex. エッジコンピューティング?)。*4
1-2. 大事な知識はソフトな知識
知識蒸留は学習結果のモデル間の転移ということがわかりましたが、どのような知識を伝えるのでしょうか? ここで大事なのは「曖昧さ(誤りの可能性)も含めたソフトな知識」となるようです。
クラス分類のタスクを考えた場合、モデルが予想するクラス(ラベル)にはHard labelとSoft labelがあります。例えば、ある画像の動物を判断する場合、「猫である(1) or それ以外(0)」で予測を出すのがHard labelです。対して「猫である可能性(0.8)、犬(0.1)、ネズミ(0.04)...」といった確率分布として予測されるのがSoft labelです。
知識蒸留では不正解に対する知識も大事な知識と考えます*5。「猫だけど、猫の中ではネズミよりも犬っぽい猫」みたいな情報にも学習の結果がつまってるよね!ってことでしょうか?
で、Soft Labelにはこの不正解情報があるので、「教師モデルによるSoft Labelの予測と同じ予測を出せるように生徒モデルを学習させれば、知識が転移できる」という感じのようです。

ところでニューラルネットワークのクラス分類の出力はSoftmax関数を使って出されることが多いそうです。 知識蒸留で使うのは温度付きSoftmax関数と呼ばれるもので、温度(T)が加わっています。 Tの値を大きく(温度を上げる)することで、重要視している不正解ラベルの確率を強調して学習に利用することができるそうです。「温度を上げて情報を一方から他方に移す」から蒸留なんですねー。

1-3. 自己蒸留 ~Be Your Own Teacher~
知識蒸留においてやりたいことが大体わかりました。モデルを小さくできて便利な知識蒸留ですが、以下のような課題が指摘されています。
- 知識転移の効率が悪い:生徒モデルが教師モデルの全ての知識を受け継げるわけではなく、精度で劣りがちになる
- 適切な教師モデルの設定が大変:目的に合った教師モデルを別途デザインし、学習させるのが試行錯誤と時間がかかり大変
どちらも教師ー生徒で別々のモデルを使っていることで生じていそうな課題です。
「・・・それならどっちも同じモデル(自分自身)にしちゃえば良いんじゃない?」
「やってみたら精度も上がっちゃったよ!」
っていうのが自己蒸留(self distillation)のようです(文献②)
下図の通り、左から右に向かって層が深くなっていく元のモデル(ResNet)を浅いセクションに分割します。浅いセクションを生徒、もっとも深いものを教師ととらえます。右から左へと戻る3色の矢印で自己(教師)の出力結果を、(生徒の)学習にフィードバックさせている様子がわかります。

モデル一つで済むのは便利ですね。
1-4. どうして自己蒸留で精度が上がるの?
ところで、なぜ知識蒸留を同じモデルで行うと精度が上がるのはなぜでしょうか?
文献②中では、①平坦最小解(flat minima)、②勾配消失(vanishing gradients)の軽減、③識別力の高い特徴量(discriminating feature)の抽出、といった観点で考察が行われています。
①平坦最小解は耳慣れない単語ですが、直感的には以下の図のようになります。

浅いニューラルネットワークは尖った最小解に陥りやすい一方で、深くパラメータ数の多いモデルは平坦な最小解に収束する可能性が高くなります。尖った最小解のモデルはデータのバイアスに弱く、トレーニングデータに対する精度が良くても、テストデータに対しては上手く機能しない可能性があります。一方で、平坦な最小解となっているモデルはデータセット間の多少のズレに対しても頑健性があり、よりロバストなモデルになっている可能性が高くなります。*6
著者らは「Self distillationでもこの平坦最小解をみつけられているのではないか?」と仮説をたて実験を行なっています。
以下の図の通り、Self distillationありとなしのモデルを比較すると、ありではパラメータにノイズを加えても精度が下がりにくく、損失が増えにくいという結果になりました。ノイズに強いのでより平坦(flat)なモデルになっているのでは?ということのようです。*7

1-5. どうして自己蒸留で精度が上がるの? part 2
以上のように元文献中でも考察は行われていますが、Self distillationで精度があがるというのはやっぱり結構な謎らしく、今年の初めにはThree mysteries in deep learning: Ensemble, knowledge distillation, and self-distillation」(Microsoft Research Blog)という記事が出ています。これは以下の文献の著者自身による解説です。
「複数のモデルを組み合わせたアンサンブルで精度が上がるのは何故か?」という問いから出発し、Self distillationの精度上昇について議論されています。
著者らは画像認識のタスクにおいてデータ構造が持つ特徴に着目し、「multi-view」と名付けています。例えば、ネコを認識する場合、ニューラルネットワークは複数の視覚的特徴(ex. 耳、目、ヒゲ、肉球・・・)を見て、ネコとクラス分類をおこなっている、といった感じです。
ですが、データセットの画像全てで、分類に使われる視覚的特徴が全部写っているわけではなく、一部の特徴しか写っていないもの(ex. 顔のアップ、後ろ向き・・・)もたくさんあります。
著者らの理論によると、このようなmulti-viewデータで学習を行ったニューラルネットワークについて、「学習過程のランダムさ(ex. 初期値, random seed)に従って、視覚的特徴のサブセットを素早く学習する」性質があるそうです。*8
この性質から、異なるランダムな初期化を行ったモデルは、それぞれ異なる視覚的特徴のサブセットを学習していることが想定されます。なので、複数のモデルを組み合わせれば(ensemble)、全体として認識できる特徴が増えるのでテストでも精度が上がる、というわけです。*9

以上がアンサンブルで精度が上がることの概略です。
では、モデルが自己だけのSelf distillationではどうなるでしょうか?
Self distillationの場合、異なる初期値の同じモデル(Teacher、Student)で、それぞれ異なる視覚的特徴サブセットを学習します。さらに、StudentはTeacherの学習した知識を受け継ぐ(蒸留)ように学習を行っているので、モデル2つ分の個々のサブセットのアンサンブルを学習できたかのようになります*10。したがってSelf distillationを行うことで、同じモデルを使っていてもアンサンブルのように精度が高くなる、ということのようです。

1-6. かわいい生徒には負荷(ノイズ)をかけよ? ~Noisy Student~
自己蒸留がどこから来たのか大体わかりました。続いて文献③ Noisy Studentについてですが、こちらは以下の日本語記事がわかりやすいです。
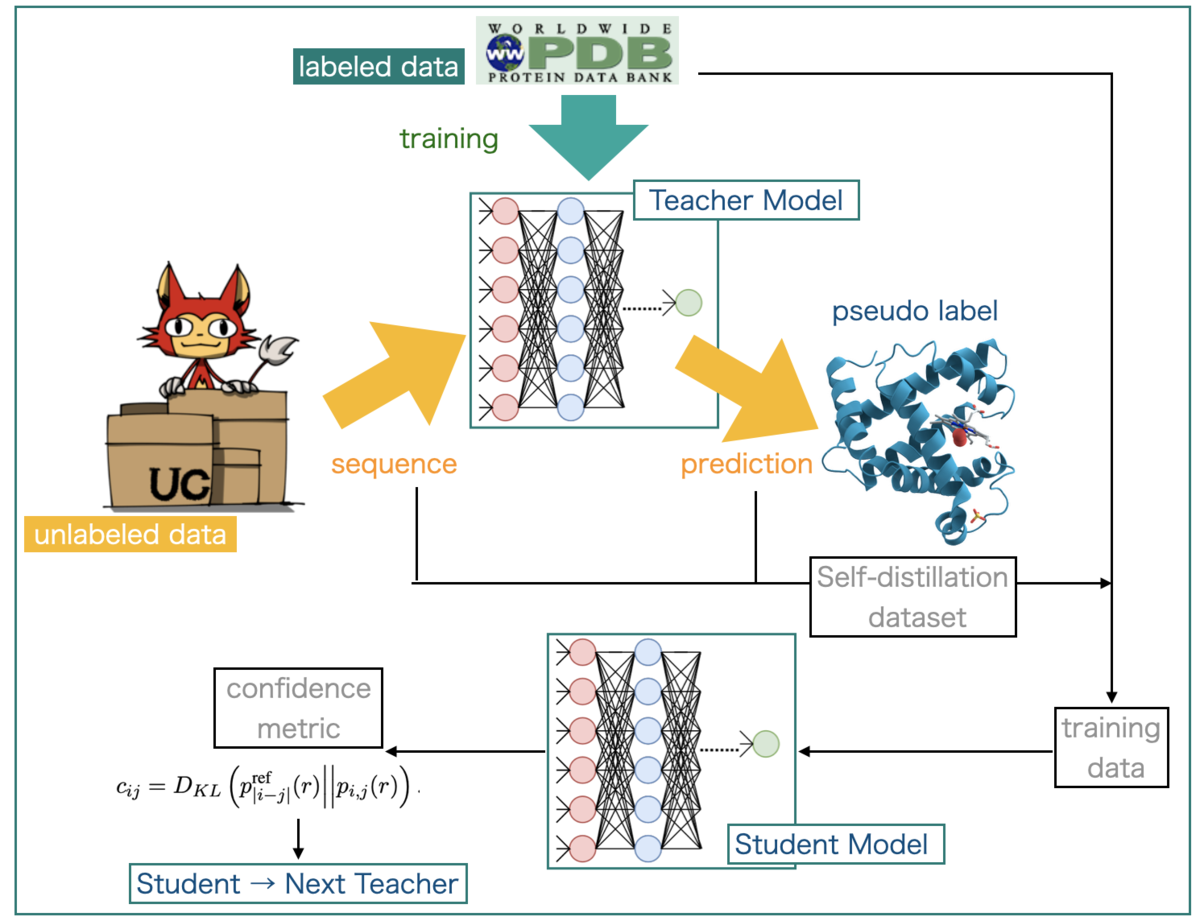
ラベル付きデータで学習した教師モデルをつかって、ラベルなしデータの予測を行い「擬似ラベル」を付与します。 元々のラベル付きデータと、擬似ラベルのデータの両方を使って生徒モデルを訓練するのが自己訓練(Self Training)と呼ばれるモデル学習方法だそうです。
Noisy Studentでは、この生徒モデルの学習の際にさらに「ノイズをたくさんかけて」学習させ、得られたモデルを新たな教師モデルとして利用して、同じことを繰り返していくそうです。

このように負荷をかけて訓練した生徒モデルは、より精度が高く、ロバスト性のあるモデルとなるようです。
Noisy Studentが通常の知識蒸留と異なる点は2つ。
- 知識蒸留では(通常)ノイズを使わない
- 知識蒸留の生徒モデルは教師モデルよりも小さい(速さを上げるため)が、Noisy studentは同じかより大きいモデルを使う
生徒モデルのキャパシティを上げつつ、ノイズを追加することで学習を難しくすることで、教師モデルよりも良いモデルを作ろうとする点で、Noisy Studentは「知識拡張(knowledge expantion)」の手法と捉えることもできる、と文献では指摘されています。
2. AlphaFold2でのSelf distillation
だいたいやりたいことがわかったのでAlphaFold2でSelf distillationがどのようにつかわれているのか見てみましょう!
まずは、ずばり用語がでてくるSupplementary Information 「1.3 Self-distillation dataset」です。
2-1. Self-distillation dataset
ここでは、Self-distillationのデータセットを準備した手順が書かれています。
AlphaFold2は配列を入力として立体構造を出力するので、ラベルを実際のタンパク質の構造とすることができそうです。 従って、ラベル付きデータとして「PDBデータセットの配列と構造の組み合わせ」を使うことができ、ラベルなしデータとしては「Uniprotから抽出した配列」を使用しています。
ラベルなしデータはより正確には、UniClust30データベース(UniProtKBの配列をペアワイズ配列相同性30%レベルでクラスター化したもの)にフィルタリングをいくつかかけたものを用意しています(計:355,993配列)。例えば、UniClust30の各クラスターについて多重配列アラインメント(MSA)を計算した後、他の配列のMSAにも出てくる配列を除くといった操作を行なっています。*11
次に、ラベル付きデータをモデルで学習し教師モデルとしています。学習のこの段階ではモデルを1つだけ使用しており、「single (no re-ranking) "undistilled" model」と呼んでいます。最終的なモデルは複数のモデルのアンサンブルで、各モデルの予測をスコアでランク付けしてから出力しているようなので、それとの違いからネーミングしているようです。
この教師モデルで、先に用意したラベルなしデータセットの構造を予測して擬似ラベルとし、自己訓練に用いています。

また、さらにデータの拡張(extra augmentation)として、均一にサンプリングしたMSAを蒸留データセットに追加しています。
以上が、self-distillation datasetの用意です。
2-2. Training data
データセットが準備できたのでトレーニングです(SI 1.2.4 Traning data)
トレーニングに用いたデータは「self-distillaion dataset」と「Protein Data Bank」からの構造をハイブリッドしたもので、75%の確率で前者から、25%の確率で後者からとって組み合わせています。
学習時にはこのデータセットを複数回ループして使用していますが、さらに確率的なフィルタリング(SI 1.2.5)、MSA前処理工程(ブロック削除 (SI 1.2.6)、クラスタリング (SI 1.2.7))、残基クロッピング(SI 1.2.8)を加えています。なので、学習のエポックごとに、それぞれ違う標的タンパク質を、違うMSA、異なる領域の切り取り方(cropping)で処理している可能性があります。
ところで、AlphaFold2は「Noisy Student」(文献③)に類似した手順を実行した(SI 1.3)とのことですが、加えたノイズは何でしょうか?
文献③ Figure 1を再度みると、self-distillation datasetに追加したMSAデータ(extra augmentation)や、学習時実行しているドロップアウト(SI 1.11.6)などがノイズに相当しそうです。
以上をふまえて、学習の工程は以下のようになるでしょうか?

2-3. Confidence metric (KL divergence)
最後に、「SI 1.3 Self-distillation dataset」で出てくる信頼性の指標(confidence metric)もみておきましょう。
これは「カルバック・ライブラー情報量(Kullback-Leibler divergence, KL divergence)」によるものです。
公開されたAlphaFold2の指標は著者らがplDDTと呼ぶものですが、自己蒸留の学習の段階ではまだ開発されていなかったらしく、代わりに使っていた指標のようです。(「plDDTをこの段階で使っていたとしても同じような結果が得られただろう」とのこと)
・・・KL divergence。強そうですけどなんなんですかね??
「Wikipedia - カルバック・ライブラー情報量」によると、KL divergenceは「2つの確率分布の差異を計る尺度」とのことです。「確率変数(X)に関してデータから得られる情報量の平均値」を表していることから、「情報利得(information gain)」とも呼ばれるそうです。
こんな感じ・・・

AlphaFold2の場合は、「予測された残基の各ペア(i, j)」について、「ペアごとの距離の分布(pairwise distance distribution)」と「その残基間隔についての参照分布(reference distribution)」との間でKL divergenceを計算しています(pairwise metric, c_ij)。
このペアごとの値(c_ij)を j について平均をとって、残基 i についての信頼性指標(confidence metirc, c_i)としています。この「残基ごとの信頼性指標が大きいことと、予測精度の高さに相関がある」ことがわかったそうです。

以上のような感じですが、何を計算しているのか?私には難しくてよくわかりません。
特にreference distributionがわからない…
AlphaFold2解体新書の該当箇所の注によると、「参照分布の配列間隔(sequence separation)」は、「アミノ酸配列(1次構造)上でどれだけ離れているか?」のことのようです。確かに「i と jの差分の絶対値」で表されているので、「i - j 間のアミノ酸残基数」と捉えて良さそうです。
ランダムにサンプリングした配列を使って、特定の配列間隔について分布の平均をとっているということは、「(残基の種類関係なく)一定の残基数分、アミノ酸配列上で離れた2残基が、立体的にはどのような距離をとるか?一般的な傾向の分布」を考えている、と解釈できるかもしれません。
一方で、pairwise distance distributionは「(残基の種類を含めた)特定のアミノ酸のペアに着目した場合の立体的な距離」と解釈できそうです。
従って、ここで計算されているKL divergenceは、「配列間隔だけを考えた一般的な距離(reference)」と「アミノ酸の種類も考えたペアの距離(pair-wise)」の2つの分布の差異を計る指標となりそうです。
これなら「指標の値が大きい(分布の差異が大きい)」ほど「特定アミノ酸ペアの残基間相互作用の特徴を学習したモデルによる予測結果」ということになるので、「精度の高さと相関する」というのも納得できるかもしませんね。*12

まとめ
以上、ディープラーニングっぽい用語「Self Distillation」とそのAlphaFold2での利用箇所についてでした。賢い方々の日本語解説記事をよんで、なんとなく雰囲気はわかったものの、具体的にどういう操作をおこなっているか?というところまでは理解できませんでした。まだまだ基礎知識が足りていないです。
とりあえず「精度を上げるための学習の手法で、同じアーキテクチャのモデルで教師役と生徒役の2役をこなす知識蒸留」という雰囲気でした。
また、AlphaFold2では「ラベルありのPDBデータ」を使って教師モデルの学習を行い、「ラベルなしの配列のみのデータ」に対する「構造予測(擬似ラベルの生成)」を行うことでSelf-distillationデータセットを用意する、といった利用がなされているようでした。
KL divergenceはよくわかりません!
ところで、バリバリ(?)の深層学習の論文を初めてまともに眺めましたが「ものすごい比喩を多用するなー」という印象をもちました。ひたすら数式やアルゴリズムが書いてあるだけなのかと思っていたので予想外でした。ネーミングも凝ってるしインパクトや親しみやすさも大事な分野なんですかねー???
今回も雰囲気と憶測だけで適当に書いているので間違いが多そうです。ご指摘いただければ幸いです。
ではでは!
*1:AIの偉い先生らしい
*2:参考日本語記事① 「Distilling Knowledge in a Neural Network 記事② 「Deep Learningにおける知識の蒸留」
*3:文献①では教師・生徒という呼び方はされていませんが、後続の蒸留に関する文献では一般的に使われている呼び方のようです。
*4:図は Alkhulaifi A, Alsahli F, Ahmad I. 2021. Knowledge distillation in deep learning and its applications. PeerJ Comput. Sci. 7:e474を利用して作成 CC-BY 4.0
*5:「dark knowledge」という呼び方をしている文献もあるようです
*6:このあたりは「損失平坦性により過適合を抑える」話として、書籍「[深層学習の原理に迫る](https://www.amazon.co.jp/深層学習の原理に迫る-数学の挑戦-岩波科学ライブラリー-今泉-允聡/dp/4000297031)」今泉允聡 著(第4章)でも取り上げられています。また、元になっている文献は「On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima」arxiv:1609.04836v2です。
*7:テストデータでは比較しなくて良いんですかね??
*8:もう一つ「視覚的特徴では分類できない少数の残りのデータは記憶する」という性質も指摘しています。この主張から、単一のモデルの学習では取りこぼす視覚的特徴があるのは、その特徴を学習するのに十分なデータが無いからで、モデルのキャパシティが足りないわけでは無い、ということが示唆されます。学習できた一部の特徴だけでほとんど分類できてしまうので、分類できなかった残り少ない画像だけでは残りの特徴の学習には不十分、というわけです。
*9:初期値が異なることに着目しているのは、「パラメータが初期値からあまり大きくは動かない」という指摘があり、その場合「初期値が異なれば学習後のパラメータもモデル間で異なる」と考えられるからのようです。文献中で比較されている関連(類似?)する話題としてNTK(Neural Tangent Kernel)、レジームというのがあるそう。NTKは線形な特徴選択なのでディープラーニングとは話がかわってくるみたい? NTKの日本語解説記事「Neural Tangent Kernel(NTK)の概要」。よくわかりません。。。
*10:さらにStudentを次のTeacherとして学習を繰り返せば、3つ、4つ、、、と含意されるモデルが多くなることになると思います。
*11:参考:macでインフォマティクス「UniProtKBデータベースを3つのレベルでクラスタリングしたUniclustデータベース」
文献 Milot Mirdita, Lars von den Driesch, Clovis Galiez, Maria J. Martin, Johannes Söding, Martin Steinegger,
Uniclust databases of clustered and deeply annotated protein sequences and alignments,
Nucleic Acids Research, Volume 45, Issue D1, January 2017, Pages D170–D176
*12:雰囲気だけで考えているので、間違っていそう。。。